
Et IBM-ledet forskningsprosjekt innen den forholdsvis nye disiplinen «kognitiv databehandling» («cognitive computing»), Synapse (en forkortelse for Systems of Neuromorphic Adaptive Plastic Scalable Electronics), har realisert en viktig milepæl: De har framstilt prototyper på to brikker til en helt ny type prosessor som reproduserer hjernens måte å behandle data på, hvilket vil si at den bygger på en helt annen databehandlingsmodell enn den som ligger til grunn for alle dagens datamaskiner, kjent som Von Neumann-modellen.
Von Neumann-modellen innebærer grovt sett at man har en sentral enhet for å utføre beregninger, et minne for å lagre data og instruksjoner (programmer) om hvordan data skal behandles, og en buss for å befordre trafikken mellom minne og sentralenheten. Data i minne skrives stadig over. Ting skjer svært raskt, men få prosesser kjøres samtidig.
Hensikten med Synapse er ikke å erstatte datamaskiner etter Von Neumann-modellen. Man ønsker i stedet å lage elektronikk for å løse en oppgavetype som mange tiårs erfaring viser at Von Neumann-modellen ikke duger til: Behandling i sanntid av enorme mengder data innhentet gjennom sensorer, tilsvarende det som skjer i hjernen hos mennesker og andre pattedyr.
Man ser for seg muligheten for et verdensomspennende nettverk av havsensorer som fanger opp myriader av informasjon om bølgehøyde, vindretning, temperatur, strøm og så videre, og som er knyttet til en datamaskin med kunstig intelligens for å lære å se hvilke mønstre som varsler flodbølger eller andre farer. Man ser også for seg for eksempel intelligente hansker til bruk i lagerrom, med et utall sensorer for lukt, temperatur og lys, som lærer seg mønstre assosiert med uønskede fenomener som råte, feilplassering, tomme hyller med mer.
Tanken er at dette kan realiseres ved å etterlikne elektronisk det man observerer i hjernen. Det skal følgelig blant annet ikke være noe klart skille mellom program og data, og minne skal ikke overskrives. Svært mange ting skjer samtidig, men «klokkefrekvensen» behøver ikke være seg høy. Hjerneaktivitet måles i millisekunder, mot nanosekunder i tradisjonelle datamaskiner.
Maskineriet som utvikles i Synapse-prosjektet skal ha to andre karakteristikker som også er typisk for hjernen: Det skal på dynamisk vis kunne endre seg selv i samspill med sine omgivelser – inntrykkene, det vil si dataene, hentet gjennom sensorene – og det skal være nøysom med hensyn til både omfang og energiforbruk.
Prosjektet finansieres gjennom Pentagons forskningsorgan Darpa, og omfatter forskere fra mange disipliner og fra prestisjeuniversiteter og forskningsinstitusjoner som samarbeider med IBM, blant dem Lawrence Berkeley National Laboratory, Columbia University, Cornell University med flere. Forskere fra flere av IBMs laboratorier deltar, blant annet fra Almaden, Zürich og India.
Prosjektets leder, Dharmendra Modha fra IBM, brukte skissen nedenfor under et foredrag i juni for å illustrere de grunnleggende forskningsgrenene som inngår i kognitiv databehandling (foredraget er filmet og lagt ut på web: Cognitive Computing: Neuroscience, Supercomputing, Nanotechnology):
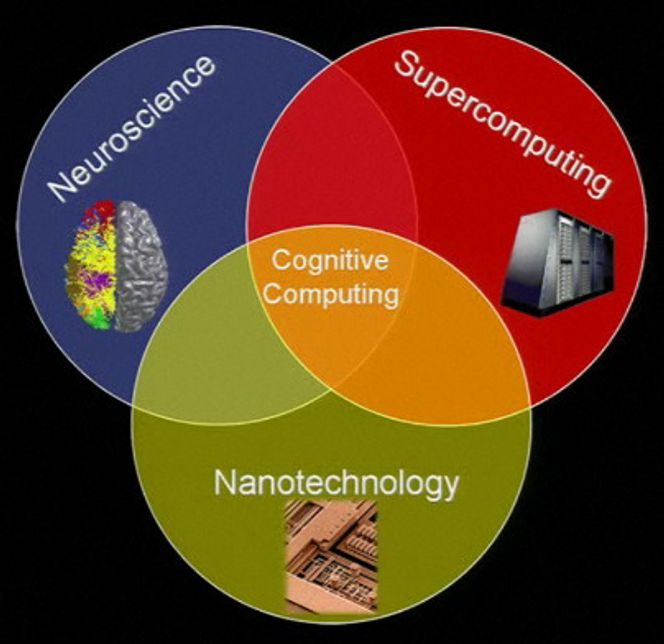
Behovet for kompetanse om nervesystemets anatomi, oppbygging og virkning – blant Synapse-forskerne er det også psykologer – trenger ingen forklaring. Poenget med nanoteknologi er å nå målet om kompakt og energigjerrig elektronikk.
Superdatamaskiner er påkrevd for å teste hypoteser om hjernens struktur, dynamikk og funksjon, gjennom simuleringer.
I november 2009 kunngjorde IBM at de hadde nådd to viktige milepæler innen hjernesimulering: En algoritme for å måle og kartlegge forbindelsene mellom hjernebarken og den underliggende hjernemassen, og en ny hjernebarksimulering tilsvarende hjernebarken på en katt. Både kartleggingsalgoritmen, «BlueMatter», og hjernebarksimuleringen kjøres på supermaskiner av typen Blue Gene.
IBM beskriver den nye milepælen, det vil si de to prototypene, som de første brikkene spesielt konstruert med tanke på kognitiv databehandling.
De omfatter ingen biologiske elementer, men er realisert med digitale kretser i silisium. De beskrives som «nevrosynaptisk kjerner» inspirert av kunnskap innen nevrobiologi, der minne, beregning og kommunikasjon er integrert. Minne svarer til nervesystemets synapser, beregning til nevroner og kommunikasjon til aksoner.
Prototypene er realisert i en 45 nanometers prosess i CMOS (complementary metal–oxide–semiconductor) med SOI (silicon on insulator). Hver omfatter 256 «nevroner». Den ene omfatter 262 144 programmerbare «synapser» (minne). I den andre er det 65 536 «lærende synapser», som altså «programmerer seg selv» ut fra dataene de mottar gjennom sensorer. Det er faste programmer, minne og prosessor er integrert, og kretsen etterlikner det man antar er hjernens funksjonsmåte: Prosesseringen er hendelsesdreven og distribuert, og svært mye skjer parallelt.

Testing av enkle applikasjoner innen navigering, kunstig syn, mønstergjenkjenning, assosiativt minne og klassifisering beskrives som vellykket.
Det er stor avstand mellom disse prototypene på kjerner for framtidige brikker innen kognitiv databehandling og hjernesimuleringene som kjøres på BlueGene-maskineri. Hjernebarken til en katt ble simulert i en modell med en milliard nevroner og 10 000 milliarder synapser. Simuleringen gikk i trinn på 0,1 millisekund, og det tok fra 10 til 100 millisekunder superdatamaskintid å gjennomføre ett millisekund hjernebarktid.
Skal prototypene nå opp til denne modellen, må tallet på nevroner ganges med 2 millioner, og tallet på synapser med 30 millioner. Siden modellen tilsvarer 4,5 prosent av den menneskelige hjernen, vil det da likevel fortsatt være langt igjen.


IBMs uttalte langsiktige mål er å bygge et system av brikker som omfatter 10 milliarder nevroner og 100 000 milliarder synapser. Det skal få plass i en enhet på maksimalt to liter, og nøye seg med én kilowatt strøm.
Forskere tilknyttet Synapse understreker at det ikke dreier seg om å konstruere en erstatning for den menneskelige hjernen, men om å lage nøysomt og beskjedent datamaskineri for å løse problemer som i dag er uløselige.
Nestleder Horst Simon ved Lawrence Berkeley National Laboratory understreker også at man er svært tidlig i prosessen. Han peker på at da man for hundre år siden prøvde ut løsninger for mekanisk flukt, måtte man prøve og feile før man kom fram til det mest hensiktsmessige. I stedet for naturens løsning, med bevegelige vinger for både oppdrift og framdrift, endte man på en annen modell, med faste vinger for oppdrift og motor for framdrift. Innen kognitiv databehandling gjelder det ikke å kopiere selve hjernen, men å gjenskape naturens løsninger på hensiktsmessig vis. Simon mener man innen kognitiv datahandling fortsatt er i den fasen hvor man er i ferd må finne ut av hva man skal velge, av «faste» og «bevegelige» vinger.
Les også:
- [08.08.2014] Denne prosessoren skal etterligne hjernen
- [05.12.2012] Styr mobilen med tankene
- [19.11.2009] Hjernesimulering skal gi bedre IT-systemer


