
Spredt over fire artikler i Wall Street Journal, beretter journalist Amir Efrati om hvordan Google de kommende månedene vil gradvis slippe ny, semantisk teknologi til i sin søketjeneste. Virkningen vil bli langt sterkere enn justeringene som ble innført i mars 2009 (se artikkelen Google blir smartere).
Artiklene bygger på intervjuer med blant annet Amit Singhal, hjernen og lederen bak Googles søketeknologi, og Danny Hillis, medgründer i Metaweb Technologies, et selskap spesialisert på semantisk teknologi som Google kjøpte i juli 2010. Intervjuene med de navngitte kildene suppleres av informasjon fra anonyme innsidere.
Offisielt vil ikke Google kommentere det som er Afratis hovedkonklusjon, at omfattende endringer vil bli innført de kommende månedene.
Endringene vil ikke bare gi bedre treff på søk. De skal også sikre at brukere bruker mer tid på Googles egne sider, i stedet for straks å forsvinne til andre sider.
En viktig endring for alle som driver informasjons- og næringsvirksomhet på nett er at de må lære seg nye metoder for å sikre at de kommer høyt opp på trefflistene, blant annet såkalt «semantisk tagging».
De fire artiklene er:
- Google Gives Search a Refresh
- What Google’s Search Changes Might Mean for You
- Google Search Revamp: A Step Closer to AI (AI står for «artificial intelligence»)
- With Semantic Search, Google Eyes Competitors
Det er verdt å merke seg at hovedkonkurrenten til Google på dette området ikke er søketjenester fra Microsoft eller Yahoo, men det sosiale mediet Facebook.
Facebook er Googles sterkeste utfordrer på annonsemarkedet, og de ligger an til å styrke seg ytterligere fordi Facebook-brukere oppholder seg langt lenger på Facebook-sidene enn Googles på Google-sidene.
Afrati anfører en tredje grunn til at Facebook er en alvorlig konkurrent til Google: De er i ferd med å bygge opp en svært omfattende database over entiteter, det vil si mennesker, steder, ting, filmer, matretter, feriemål og så videre, det vil si alt brukerne deres er opptatt av og omtaler på sine «vegger». En slik database vil kunne danne grunnlaget for en framtidig semantisk søketjeneste i Facebook.
Dagens standardtjeneste i Google er søk etter nøkkelord. Teknologien er forfinet gjennom en algoritme som rangerer treff etter en rekke kriterier for relevans. Brukeren kan justere i hvilken utstrekning rangeringsalgoritmen også skal ta hensyn til ens egne tidligere søk, hvor man befinner seg og så videre.

Semantisk søk innebærer at søketjenesten ikke bare skal satse på å gjenkjenne nøkkelord, men også på å forstå hva man faktisk er på jakt etter. Dette kan gi dramatiske forbedringer i søketjenesten, fordi det skilles mellom like ord med helt ulik betydning. «Nordlys» kan være et lysfenomen i Norden, men det kan også være navnet på en båt. «Jaguar» er et dyr og et bilmerke. Og så videre.
Metaweb, som Google kjøpte for snart to år siden, søkte å løse dette ved å innføre en database for entiteter. Deres tjeneste, Freebase, inneholdt 12 millioner entiteter da Google kjøpte dem. I dag inneholder Freebase 20 millioner entiteter. Grensesnittet med de merkelige grafene er ikke spesielt hensiktsmessig utformet, men prøv å taste for eksempel «henrik ibsen» i søkefeltet øverst: Det dukker opp et vindu med en liste over ulike entiteter som svarer til søkestrengen: Henrik Ibsen som dramatiker, Henrik Ibsen som boktittel, Henrik Ibsen som musikkspor (et spor fra albumet Naar vi døde rocker av gruppen Black Debbah) og så videre.
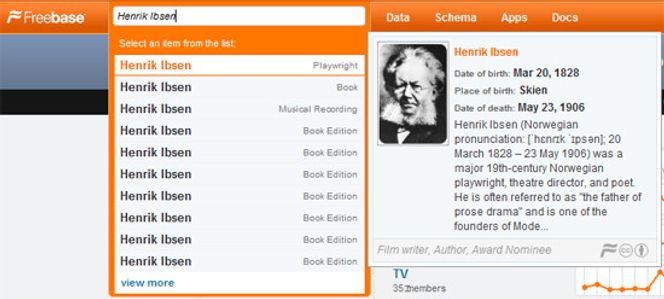
Velger man Henrik Ibsen som dramatiker, får man en kort oversikt over liv og verk, en lenke til den relevante artikkelen i Wikipedia, samt lenker til relaterte entiteter på Freebase. Disse relaterte entitetene omfatter alt fra steder som Skien og Vår Frelsers Gravlund i Oslo, til filmer basert på Ibsens stykker og en oversikt over hvem Ibsen har influert, for eksempel George Bernard Shaw og James Joyce.
Det er lett å se for seg hvordan en kombinasjon av Freebase og dagens Google-søk kan både berike brukerens tilegnelse av kunnskap og få folk til å tilbringe mer tid på Googles sider. Til Henrik Ibsen som dramatiker, kan man for eksempel legge inn lenker til Google Books-utgaver av Ibsens samlede verker. At dette vil styrke Google som annonsemedium er også innlysende. Det er også enkelt å se for seg hvilke fordeler Facebook vil kunne trekke fra en tilsvarende database. Nevner man en entitet i databasen, kan Facebook sørge for at det automatisk forsynes med en underliggende lenke.
I et video-intervju med Bloomberg i forrige uke forteller Singhal (sjefen for Google-avdelingen som utvikler søketjenesten) at de har bygget opp en database «med flere hundre millioner entiteter», altså minst ti ganger større enn databasen som Freebase tilbyr i dag. Beskrivelsen som Afrati gir av hvordan denne enorme databasen fungerer, er helt sammenfallende med det man i dag kan oppleve på Freebase (som Afrati ikke nevner).
Til Afrati sier Singhal at Googles foreløpig interne variant av Freebase-databasen er utvidet til mer enn 200 millioner entiteter. Dette er gjort gjennom egne algoritmer som trekker ut og organiserer informasjon. Google har også fått tilgang til flere offentlige informasjonsdatabaser, blant dem CIA World Factbook.
Google nekter å si hva de kommende endringer vil bety for dem som er opptatt av å komme høyt oppe på trefflister.


Til Wall Street Journal sier en tidligere leder i Yahoo, Larry Cornett, at man bør sette seg inn i åpne standarder om semantisk tagging, gitt av blant andre W3C. Nettstedet Semantic Web har nyheter om temaet, relevante lenker til bakgrunnsmateriale og dessuten en RSS-feed.
Metaweb-medgründer Danny Hillis anbefaler Learning Resource Metadata Initiative der versjon 0.7 av LRMI-spesifikasjonen er omtalt.
Takten i den kommende fornyelsen av søketjenesten til Google kan man bare spekulere i. Den gradvise innføringen av banebrytende nyheter de kommende månedene kan også vare i mange år. Singhal har i sine intervjuer understreket at perspektivet går over mange år. Han har også sakt at han drømmer om å gjøre Google like hjelpsom overfor mennesker som datamaskinen i tv-serien Star Trek.