
Cognition Technologies fra Los Angeles har lansert et språkteknologisk verktøy som skal gi langt bedre resultater innen tjenester der man forventer at et dataprogram skal forstå hva et menneske mener. Dette er tjenester som generelle søk, produktsøk i kataloger, innholdsrelatert annonsering, automatisering av kundehenvendelser, etterforskning gjennom store mengder dokumenter, maskinoversettelser med mer.
Verktøyet er kommersielt tilgjengelig, med programmeringsgrensesnitt slik at det kan settes i produksjon mot valgfrie korpus og integreres i eksisterende tjenester.
Produktet beskrives som et «semantisk kart», og heter offisielt «Cognition Semantic NLP», der NLP står for «natural language processing». Det har vært under utvikling i over tjue år.

Semantic NLP skal være over dobbelt så stort som andre kommersielt tilgjengelige semantiske kart over engelsk. Det skal inneholde over 10 millioner semantiske forbindelser. En semantisk forbindelse er noe som plasserer et ord i en gitt kontekst, slik at det er mulig for programmet som mottar en ytring på engelsk å skille mellom ordenes og ordgruppenes ulike betydninger og tolke den samlede ytringen så nært opp til det som faktisk er meningen.
I kartet er fire millioner semantiske kontekster, det vil si ulike betydninger som innvirker på meningsinnholdet i andre ord. Det er videre over 536 000 betydninger av ord og vendinger, 75 000 «konseptklasser» eller samlinger av synonymer, og 506 000 engelske ordstammer.
Dette kartet gjør det mulig å skille mellom ulike betydninger av ordene man bruker i et søk, og velge de som gjør sammenhengen meningsfull. Det gir flere fordeler. For eksempel vil «pass bill» oppfattes å ha noe med lovvedtak å gjøre, ikke en situasjon i en restaurant der en annen i selskapet ber om å se regningen. En annen fordel er at programvaren oppfatter at tekster som inneholder «fatal» handler om død, selv om de ikke nødvendigvis inneholder ordet «death».

På sitt nettsted gir Cognition anledning til å prøve teknologien mot tre forskjellige baser: amerikanske rettsavgjørelser lagret i Public.Resource.org, en helsefaglig database, og Wikipedia. Demonstrasjonen gir anledning til å sammenlikne søk gjennom Cognition med søk etter de samme vendingene med disse basenes egne søketjenester. Erfaringen er jevnt over at Cognition gir langt færre treff, og at Cognition-treffene er de som er mest relevante.
Søk etter «risk analysis in financial institutions» i Wikipedia gir 34 unike treff gjennom Cognition, og nærmere 175 000 unike treff gjennom Wikipedias standard søketjeneste.
Som en ekstra tjeneste legger Cognition opp en boks der det gjengis hvordan verktøyet tolker nøkkelordene. Boksen viser at tre vendinger er valgt som relevante for søket: «risk», «analysis» og «financial institution». Den viser også at tolkingen av «analysis» som «psychoanalysis» er valgt bort. Man får altså ingen ting relatert til risiko ved psykoanalyse i finansielle institusjoner gjennom dette søket, og Cognition later derfor til å forstå at man mente å søke etter hvordan finansinstitusjoner bruker verktøy for risikoanalyse.
På den andre siden, dersom det var psykoanalyse man mente, har man anledning til å presisere det, og kjøre søket på nytt med denne tolkingen. Da plukker Cognition ut to unike treff, mens standardverktøyet gjengir over 80 000.
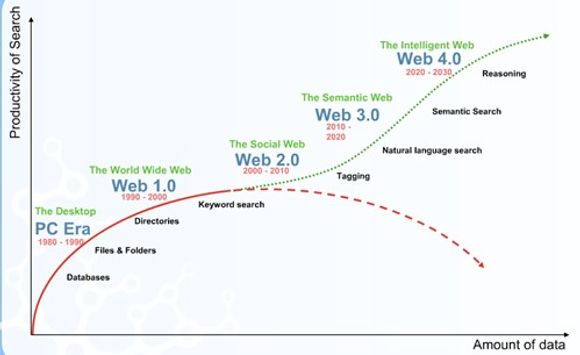
Den vesentlige gevinsten ved Cognition er større produktivitet i alle former for søk enn ved dagens teknologi basert på nøkkelord: Man finner raskere fram til relevante treff, og man belemres ikke med å måtte sjekke ut det som ikke svarer til det man er ute etter.
Cognition mener vi allerede i dag opplever en utvikling der produktivitet ved søk faller. Det finnes ulike måter å bedre denne produktiviteten: Tagging hjelper noe, og prosessering av naturlig språk gir et virkelig sprang. Håpet er å kunne utvikle teknologien videre, slik at man kan realisere ekte semantiske søk, og til slutt gi datamaskinprogrammer evnen til å resonnere på selvstendig vis.
I framstillingen nedenfor koples denne utviklingen til framveksten av Web 2.0, og deretter til de kommende generasjonene: Web 3.0 blir den «semantiske web», mens Web 4.0 blir «den intelligente web».
Les også:
- [28.05.2009] - Slaget vil stå mellom oss og Google
- [26.03.2009] Google blir smartere
- [07.10.2008] Søkeveteran gir Google svar på tiltale
- [02.06.2008] Gir datamaskiner språkfølelse
- [03.04.2007] Gir bort språkteknologi til USAs folk i Irak
- [21.02.2007] God norsk stavesjekk innen rekkevidde
- [05.10.2006] Utvikler språkteknologi for USAs spioner

