I forrige uke fikk et nytt språk for webben stempel som industristandard. Den nye standarden heter SPARQL (SPARQL Protocol and RDF Query Language) og er et språk for å formulere spørsmål. Språket er allerede tatt i bruk, blant annet innen medisinsk forskning, i oljeindustrien og i tilknytning til Wikipedia.
Les også:
- [18.01.2008] Enklere informasjonssøk med ny W3C-standard.
Blant aktørene som allerede har fått erfaring med bruken av SPARQL, er norsk Computas. Kjetil Kjernsmo, som er senior kunnskapsingeniør i selskapet, forklarer til digi.no hvorfor SPARQL er en stor nyhet.
- SPARQL kan brukes til å spørre om å få data om ting, det være seg alt fra dokumenter på webben, abstrakte ting som en værtype, til fysiske ting som en person. Når vi gjør et søk på webben, foregår det mest i form av tekstsøk. Noen har kanskje prøvd å bruke spesielle ord i sine søk - søker man på «bil og fly», forventer man å få artikler som inneholder noe om både biler og fly. På Google kan man sette et minus-tegn foran et ord hvis man vil at dokumenter med ordet ikke skal være med i resultatet, sier Kjernsmo.
- Men presise søk får man sjelden gjort på denne måten, og derfor har det blitt utviklet egne spørrespråk.
I database-systemer bruker man slike språk, men de har gjerne vært begrenset til en database.

- For å søke på en strukturert måte på et system med webskala har man derfor utviklet spørrespråket SPARQL, sier Kjernsmo.
Han forklarer at SPARQL kan brukes til å søke i data som er formulert med språket RDF. Det som er tilgjengelig slik kaller vi «Semantic Web», eller den semantiske webben.
- Eksempler på data som er formulert på denne måten er data fra Wikipedia og en stor database med stedsnavn, som man finner på henholdsvis DBpedia og Geonames, men det er mye, mye mer, milliarder av datapunkter kan det søkes i. Man bygger også broer til andre teknologier, og med GRDDL (Gleaning Resource Descriptions from Dialects of Languages) blir strukturerte data fra vanlige websider også tilgjengelig. Dette er standarder som allerede er på plass, forteller Kjernsmo.

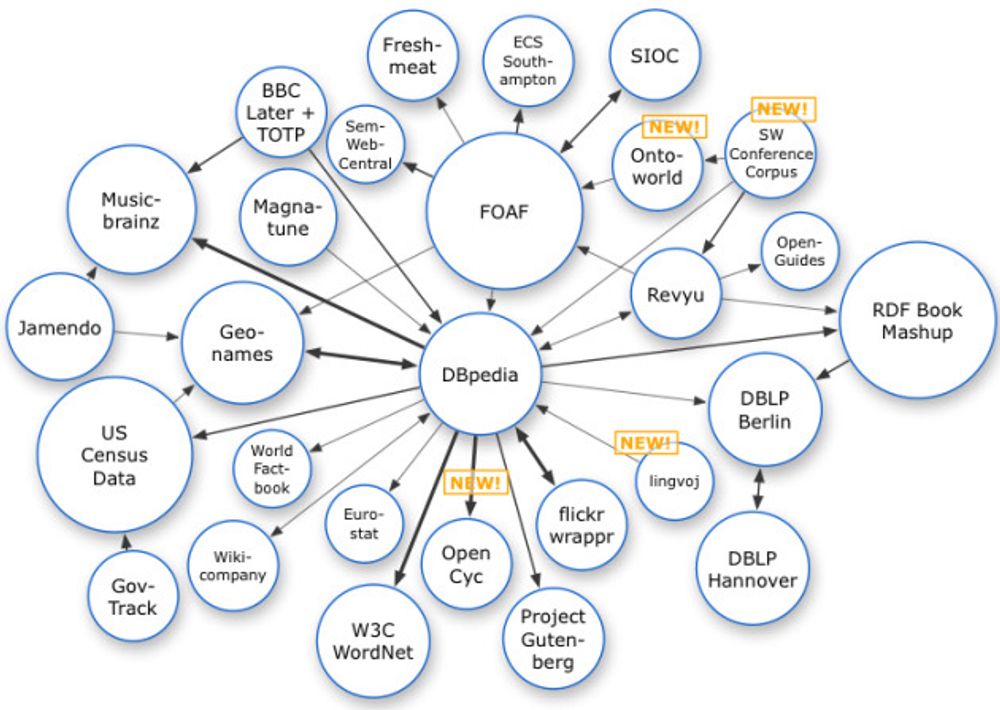
Det beste eksemplet på hvor utbredt SPARQL er, er ifølge Kjernsmo Linking Open Data-prosjektet, som ble startet i tilknytning til W3C Semantic Web Education and Outreach-gruppen for å vise bruk av Semantic Web-teknologi. Figuren nedenfor oppsummerer hvilke data som kan utforskes med SPARQL. En interaktiv versjon av figuren finnes på denne siden.
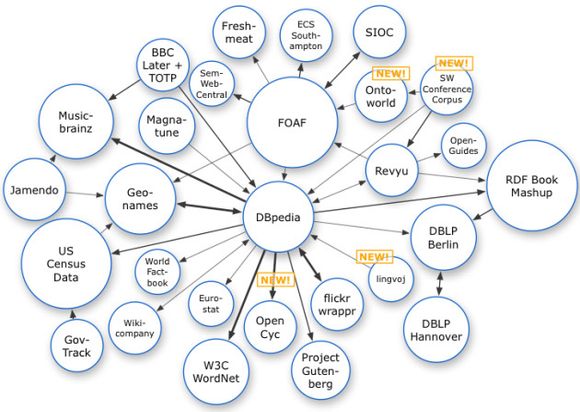
Men ifølge Kjernsmo legges det til nye datakilder hele tiden.
- I løpet av de siste dagene har dbtune.org kommet til, og det jobbes visstnok med en stor database over finansielle data, forteller han.
- Men det virkelig store blir når vi kan sende en spørring som henter data fra forskjellige datakilder. Vi er ikke helt der ennå, selv om språket kan håndtere det, men det vi ønsker å gjøre i nær framtid er spørringer som kombinerer for eksempel «gi meg hvilke bøker som er i salg, som er skrevet av en forfatter som har bodd i Bergen». Dataene har vi, vi må bare samle dem i hop under det vi kaller en «SPARQL endpoint».
- Bare tenk hva man kan få til hvis vi fikk SPARQL-tilgang til åpne artikler: «Hvilke personer med en inntekt over 5 millioner er hyttenaboer?»
Computas er blant de norske firmaene som tar i bruk SPARQL fra dag en.
- På vegne av oljeindustrien har vi fulgt utviklingen lenge, og forskningen, som har sin basis i SPARQL, kan bli tatt i bruk om kort tid, sier Kjernsmo.


For oljeindustrien er Computas vært involvert i flere prosjekter som går ut på å finne raske ekspertråd i forretningskritiske situasjoner og for å se på muligheten for automatisk å konfigurere installasjoner på havbunnen.
- Basert på bibliotekenes behov, har vi nå et prosjekt som skal gjøre det mye enklere å søke etter og navigere i kvalitetskontrollert informasjon på nettet, der SPARQL er en helt sentral komponent. Ettersom mange felter i IT-industrien har egne spørrespråk. tenker vi oss at SPARQL vil bli en sentral komponent når forskjellige systemer skal snakke med hverandre, forteller Kjernsmo.
Og det er nettopp der SPARQL skiller seg fra tidligere teknologier.
- For det første bygger SPARQL på et allerede fungerende globalt informasjonssystem, nemlig webben. For det andre er språket lagd for å brukes på tvers av svært forskjellige datakilder.
Kjernsmo mener at folk flest vil ikke se mye til SPARQL i nær framtid, ettersom språket er nokså innviklet. Det skal likevel være enklere å formulere SPARQL enn å programmere, og dermed vil ting som tidligere krevde kostbar og vanskelig programmering nå bli billigere og enklere. Dette betyr at teknologien er mer tilgjengelig og at flere vil benytte seg av den, noe som Computas håper vil føre til en stor oppblomstring av nyttige ting fra grasrota, som var slik webben vokste i starten.
I tillegg til dette, satser Computas også på et voksende kommersielt marked og forventer verdiskaping langt utover det dagens web kan gi.
Også andre aktører satser allerede på SPARQL. En oversikt over noen av dem finnes her.

