
En typisk erfaring med vanlige verktøy for drift, er at brukerne kan klage på lange responstider og trege systemer, selv om alt fra IT-siden ser ut til å være i orden. Løsningen på dette er å skaffe driftsverktøy som supplerer det tradisjonelle bildet ved å formidle et inntrykk av hvordan hele systemet oppfattes fra brukerens side.
Et verktøy som griper fatt i dette, er Citrix Edgesight, som nå har vært tilgjengelig et års tid. digi.no har snakket med Thomas Sandberg, plattformansvarlig for Citrix i Sparebank 1 Gruppen, som har positive erfaringer med Edgesight etter å ha brukt produktet noen måneder. Sandbergs ansvarsområde omfatter rundt 250 brukere.
– Citrix brukes i hovedsak for brukere på utekontorene. IT-messig er disse fordelt på forskjellige soner, blant annet har avdelinger som Liv og Skade hver sin sone. Det gir en noe komplisert infrastruktur. Til utekontorene kjører vi VPN-forbindelser over dedikerte linjer, der vi ikke har full kontroll over båndbredden. Edgesight er veldig viktig for å få en følelse av hva som skjer i den andre enden, og for å kontrollere hva som skjer i serverfarmen.

Edgesight brukes til å sjekke det som skjer i sanntid, og også til å fange opp data løpende med tanke på analyser bakover i tid.
– Dersom vi hører i ettertid at noe har gått treigt, kan vi bruke historikken i Edgesight til å finne trender og sjekke hva som skjedde på et gitt tidspunkt.
En viktig grunn til at Sandberg valgte Edgesight, er at han opplevde verktøyet som enkelt å konfigurere.

– Det er ikke mye vi har skrudd på for å tune Edgesight riktig. Andre verktøy som vi prøvde, krevde veldig mye skruing på terskelverdier for ikke å gi falske alarmer. I Edgesight har vi skrudd på til sammen to verdier. For resten har vi beholdt standardverdiene. Selve installasjonen tok en knapp halvtime, før vi kunne sette i gang med å sende ut agenter.
Edgesight-serveren kjører mot en SQL-database. Agentene sendes dels dit Citrix Presentation Server kjøres, dels til lokale arbeidsstasjoner. Sandberg bruker uttrykket «endpoint-agent» om den siste.
– Vi kjører agenter fast bare på Presentation-serverne. Vi har et titalls lisenser for endpoint-agenter. Disse installerer vi på problemarbeidsstasjoner, og avinstallerer dem igjen når vi erfarer at problemene er løst.
En «problemarbeidsstasjon» meldes til Sandberg dersom førstelinjesupport ikke greier å fikse problemet.
– Vi bruker Edgesight til å sjekke om det er feil på farmen, eller på nettforbindelsen. Hvis vi ikke finner noe der, installerer vi en endpoint-agent hos brukeren. Denne logger data som med jevne mellomrom gjøres tilgjengelig i den historiske delen av Edgesight-serveren. Den kan også innstilles på å varsle om bestemte forhold. Går vi inn i sanntid-delen av Edgesight-server, vil denne kople seg direkte til den lokale agenten.
Edgesight-serveren administreres gjennom et web-grensesnitt. Det krever Internet Explorer, men lar seg lure av IETab under Firefox.
– I den historiske delen er det fort gjort å gå seg bort, fordi det er så veldig mange muligheter. Det er lurt å lagre rapporter man bruker ofte, under «favoritter». Man starter gjerne med såkalte «summary» rapporter, som viser total oversikt over de ulike kategoriene.
Sandberg kjører Citrix i en virtualisert infrastruktur der mange driftsoppgaver lar seg automatisere, blant annet rebooting av alle Citrix-servere hver natt.
– Vi logger alt av feilmeldinger, også popper som brukere kanskje ikke fester seg ved selv. Grafen viser oversikten. Det er lett for oss å finne tilbake til selve feilmeldingen.
På skjermbildet under ser man at det er en fysisk server som melder om langt flere feil enn de andre.
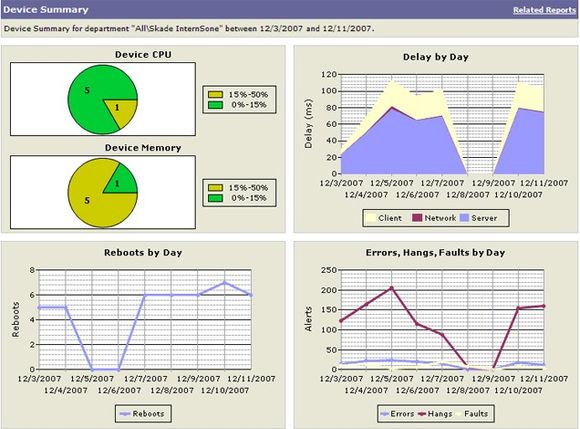
– Vi prøver å finne ut hva som gjør at den sliter. Vi kommer til å tanke den helt om. Da booter vi serveren fra nettet, og den reinstallerer, legger inn alle patcher, siste support pack fra HP og så videre. Alt skjer automatisk, og tar en times tid. Vi gjør så å si ingenting manuelt.


Rapportene var langt mer omfangsrike tidligere.
– Da vi begynte med Edgesight hadde vi mellom 1000 og 1500 alerts hver dag på mange servere. Nå er vi stort nede i 100 til 150. Innsikten har gitt oss anledning til å rydde veldig mye. Vi fant feil som vi ikke så direkte ut fra loggene, og vi oppdaget nye sammenhenger. Etter noen dager med Edgesight kan man sette i gang med systematisk luking. Jeg tror vi skal greie å få feilfrekvensen enda mer ned.
En interessant utvikling gjelder logginn-tid for vanlige brukere. Den var oppe i halvannet minutt. Nå er den nede i 20 til 25 sekunder.
Les også:
- [07.03.2008] HPs forskning skal raskere ut på markedet
- [26.04.2007] Citrix setter fart på SAP-miljøer
- [15.03.2007] Simulerer belastninger i Citrix-miljø
- [19.02.2007] Citrix-styrte bærbare kan brukes offline
- [19.12.2006] Citrix-verktøy måler ytelse til applikasjoner

