
TRONDHEIM (digi.no): Om det skyldes lekkasje i serverrommet, overspenning i strømnettet eller slitne snurredisker, er det lite som irriterer mer enn tap av data. Spesielt om du lagrer mye, og spesielt om det er andres data du lagrer.
Heldigvis tar de aller fleste backup av dataene sine. Dette er gjerne i form av én, to eller tre eksakte kopier av harddiskene, oftest på et annet fysisk sted enn originalen.
Men disker koster penger, og i en verden der datamengden øker med 40 prosent hvert år, byr det på enorme utgifter for aktører som lagrer mye. Derfor har selskaper som Microsoft og Yahoo begynt å gå over til såkalt erasure coding for å beskytte sine data.

- Lar seg ikke en gang skru på: Linux-kommando tok fullstendig drepen på pc
En bit her, en bit der
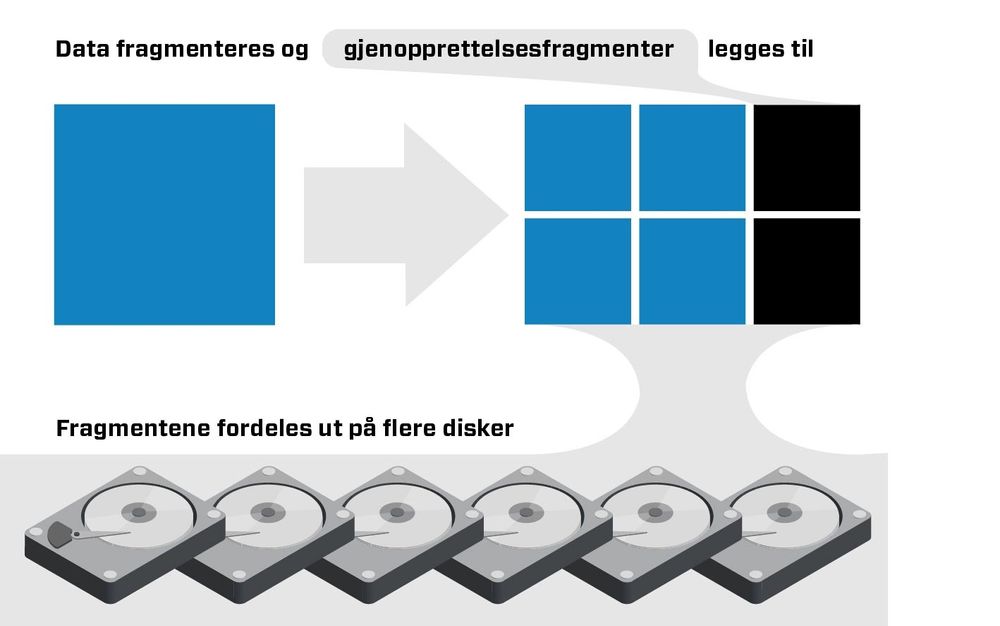
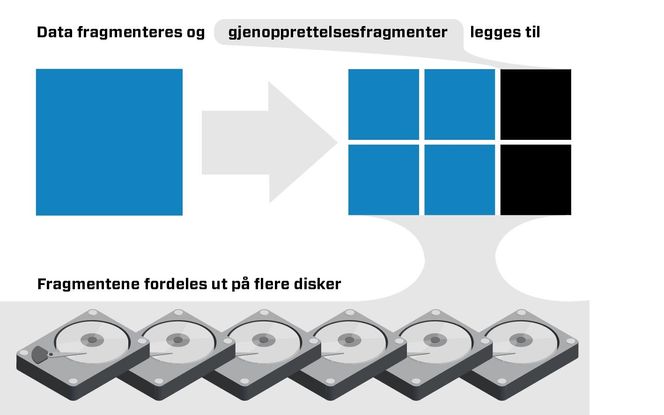
I korte trekk går dette ut på å fordele ut biter av dataen man ønsker å ta backup av på mange harddisker.
Etterpå legges det på noen ekstra biter, som kan hjelpe systemet med å gjenopprette tapte harddisker. Disse ekstra bitene kaller man redundansfragmenter.
Måten redundansfragmentene spiller sammen på i erasure coding, gjør at man trenger mindre lagringsplass og dermed færre harddisker enn tradisjonelle backup-løsninger.
- Evry på Gjøvik: Her holder nettskyen 100 prosent oppetid
Mer enn RAID
– Erasure coding er på full fart inn. Det er på mange måter en videreutvikling av RAID. Litt forenklet kan man si at et RAID fungerer slik: For å beskytte to fragmenter mot feil, legger du til et tredje fragment som inneholder summen av de to. Ekstragmentet tar like mye plass som ett av de andre, forklarer Per Simonsen, daglig leder i Optistore.
Men mens RAID vanligvis bare har ett til to redundansfragmenter, har erasure coding flere fordelt på flere disker. Dette øker sikkerheten betraktelig.
Men de som allerede har tatt erasure coding i bruk, sliter med at det tar lang tid å gjenopprette data når noe først har gått galt.
For å få bukt med ytelsesproblemene, må de i dag begrense antallet harddisker tilknyttet hver gjenopprettelsesdisk. Altså har de en større andel redundansfragmenter en det som er nødvendig for å beskytte dataen mot feil.
- Se oversikten: Så mye tjener IT-ansatte
60-70 prosent mer effektivt
– I eksisterende løsninger benyttes bare ett redundansfragment når dataen gjenopprettes. Vi bruker flere redundansfragmenter, og siden vi har kodet ekstra data inn i disse fragmentene, kan vi gjenopprette uten å lese så mye data.
– Altså leser vi fra flere disker, men vi leser mindre data totalt, oppsummerer Simonsen.


Metoden skal gjøre det 60-70 prosent mer effektivt å gjenopprette data sett i forhold til industristandarden.
I praksis betyr dette at man kan ha langt mer data tilknyttet hver gjenopprettelsesdisk, og dermed færre harddisker totalt. Forøvrig er Optistore midt i et navnebytte, og har foreløpig en nettside på Splicecode. De er en del av inkubatoren NTNU Accel.
Klar i løpet av året
De ønsker å selge programvaren som en plugin til de som bruker lagringssystemer basert på åpen kildekode, som CEPH, Swift og HDFS.
I tillegg kan bedrifter som lager proprietære lagringssystemer benytte seg av Optistores biblioteker mot betaling.
De ha allerede fått en stor norsk testkunde, og satser på å ha programvaren ute i fullversjon innen slutten av året.
- Bombesikkert: Ubåtbunker ble datasenter


