Denne artikkelen er levert av Titan.uio.no, en nettavis utgitt av Universitetet i Oslo (UiO).
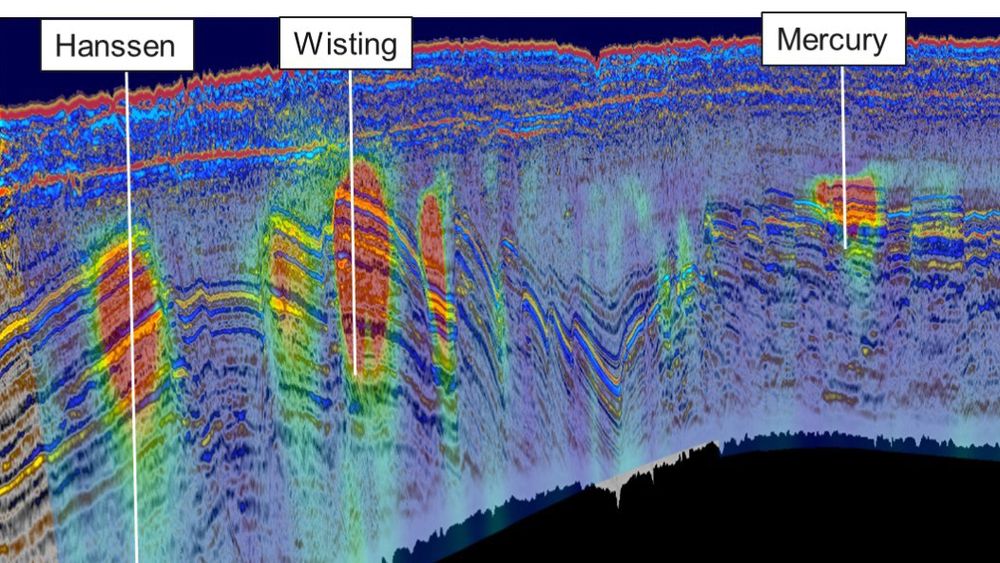
For å finne olje og gass, er man avhengig av god seismikk. Og den krever gjennomgang av store mengder rådata, noe som tar lang tid. Anders Waldeland har brukt maskinlæring og bildeanlayse for å «speede opp» prosesseringen av seismiske bilder.
– Poenget med seismikk er å identifisere lagene med forskjellige bergarter. Du vet hvor lang tid lydsignalet brukte fra det ble sendt ut, reflektert under bakken og til det kommer tilbake til overflaten, forklarer Waldeland.
Trykkbølger
Seismikk handler om å bruke trykkbølger til å kartlegge geologien i undergrunnen. Et lydsignal skytes ned i bakken.
Når lydbølgene treffer ulike geologiske lag, blir deler av lyden reflektert tilbake til overflaten av bakken. Der tas disse signalene opp og brukes til å lage bilder av de geologiske strukturene.
Oljeselskapene anvender seismikk til å finne områder med olje og gass. Rettere sagt: De identifiserer områder som med en viss sannsynlighet kan inneholde olje- og gassreservoarer. Disse områdene blir så blinket ut som interessante for prøveboring.
Bare en liten prosentandel viser seg å ha drivverdige forekomster.
Dataprosessering
– For å finne punktet der refleksjonen skjedde, må du beregne den nøyaktige lydhastigheten. Nøkkelen til riktig tolkning av seismikksignaler ligger derfor i hastighetsberegninger, sier han.
Derfor er det viktig med god dataprosessering. En av årsakene til at det er så tidkrevende å omdanne seismiske data til bilder av geologiske formasjoner, er at mye må tolkes manuelt.

Digital signalbehandling og akustikk var tema for mastergradsoppgaven til Anders Waldeland. Han syntes digital signalbehandling var fascinerende fordi det ligger i krysningsfeltet mellom to av hans favorittfag, nemlig informatikk og fysikk.
Signalbehandling
Signalbehandling er et fagfelt som handler om hvordan du kan hente ut informasjon av ulike typer signaler. Utfordringen er at et signal alltid består av ønsket og uønsket informasjon. Man skal altså få fram ønsket informasjon og samtidig fjerne støyen.

Waldeland fortsatte å jobbe med signalbehandling da han tok fatt på sitt doktorarbeid, men nå avendt på seismikk:
– Jeg har tatt utgangspunkt i kjent teknologi for bildeanalyse, som handler om automatisk tolkning av bilder, og anvendt disse metodene på seismikk. Jeg ville finne ut om bildeanalyse kan brukes til raskere å lage hastighetsmodellene for seismikk.
100 ganger raskere
– Det viser seg at metoden basert på bildeanalyse går opptil 100 ganger raskere enn den konvensjonelle metoden. Dermed er det mye tid å spare, men det trengs forbedringer i metodikken for å oppnå like høy bildekvalitet som ved bruk av de konvensjonelle metodene, forklarer Waldeland.


Den andre problemstillingen han har tatt for seg i doktoravhandlingen, dreier seg om saltforekomster i grunnen. Saltstrukturer gir ekstra høy lydhastighet, som kan gi unøyaktigheter hvis man ikke tar hensyn til saltet.
Dette håndteres i dag ved at man manuelt går inn og tilpasser hastighetsmodellene der man mener det er saltholdige lag. Også dette er tidkrevende prosesser.
3D-modell av saltforekomsten
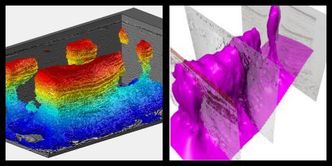
Waldeland har sett på om det er mulig å bruke dyp læring for automatisk å lage en realistisk 3D-modell av saltforekomsten. Dyp læring er en maskinlæringsmetode som er blitt populær de siste fem årene og som har revolusjonert oppgaver som ansiktsgjenkjenning og bildesøk på nettet.
Har du talegjenkjenning på telefonen, er det dyp læring som ligger bak, likeledes når det dukker opp bokser med navneforslag på bilder av vennene dine på Facebook.
Waldeland har brukt dyp læring til å trene opp algoritmer til å gjenkjenne seismiske teksturer med og uten salt. På denne bakgrunnen kan algoritmen lage automatiske saltmodeller ut fra seismiske data.
Kan bli et nyttig verktøy
Waldeland har sammenlignet slike automatiske 3D-modeller med modeller basert på manuelle tolkninger. Det viser seg å være forbløffende godt samsvar. Mye tyder derfor på at Waldelands metode kan bli et nyttig verktøy i petroleumsgeologisk kartlegging.
Flere selskaper har allerede vært i kontakt med ham, og ett av dem har så smått kommet i gang med utprøving.
– Hvorfor er saltet så viktig?
– Tar man ikke hensyn til saltet, blir det i beste fall uklare seismikkbilder. I verste fall blir det store feil. Saltet kan også, på visse steder, være en indikasjon på at det finnes et reservoar, og å ha en god tolkning av saltet kan dermed minske feilmarginen ved prøveboringer.
– Jeg liker komplekse problemer
Om valg av tema for doktoravhandlingen sier Anders Waldeland:
– Jeg liker komplekse problemstillinger. Og kombinasjonen mellom bildeanalyse og signalbehandling var noe som virkelig fenget min interesse.
Siden september 2017 har Waldeland vært ansatt på Norsk Regnesentral, der han jobber med maskinlæring og bildeanalyse.
– Det kan virke som om alle skal drive med kunstig intelligens og maskinlæring og at mulighetene er uendelige. I virkeligheten har algoritmene noen fundamentale utfordringer, for eksempel innenfor dyp læring. Vanskeligheten er å vite når de virker og når de ikke virker. Og hvis man ikke vet når man kan stole på dem, har vi ikke kommet veldig langt, påpeker han.
– Algoritmene vil alltid være regelstyrte
– For å lage algoritmer som fungerer, er vi avhengige av treningseksempler. Altså eksempler hvor vi kjenner fasiten slik at vi kan trene opp algoritmene. Vi kan lage algoritmer som lærer seg hvordan de kan skjelne mellom en hund og en katt.
– Dette virker smart, men det fungerer bare når nye bilder ligner på treningseksemplene. Tenk deg at algoritmen bare har sett svarte katter og hvite hunder. Da vet vi ikke om algoritmen virkelig har lært forskjellen på hund eller katt, eller om den bare har lært forskjellen på svart og hvit.
– Kan kunstig intelligens blir smartere enn den menneskelige?
– Algoritmene vil alltid være regelstyrte, selv om vi ikke eksplisitt har forklart dem hvilke regler som skal følges. Når algoritmene lærer seg hvilke regler som fungerer, er det ikke snakk om selvstendig tenkning. Det hele er basert på statistikk, forklarer den nybakte doktoren.


