Tirsdag denne uken ble skybaserte tjenester fra både Cloudflare og Microsoft utilgjengelige for mange kunder i mange deler av verden. Nå har begge selskapene kommet med sin såkalte post mortem, hvor de forteller om hva som egentlig gikk galt.
La oss begynne med Cloudflare, som fikk problemer ved 19 av selskapets datasentre, og akkurat disse 19 datasenterne betjener en betydelig mengde av den totale trafikken til selskapet. Dette berørte mange nettsteder og tjenester som er avhengige av disse tjenestene.
De 19 største ble berørt
Ved akkurat disse 19 datasentrene er systemene satt opp med en ny arkitektur som er utviklet for å være mer fleksibel og motstandsdyktig enn i de øvrige datasentrene. Denne arkitekturen kalles internt for Multi-Colo PoP (MCP).
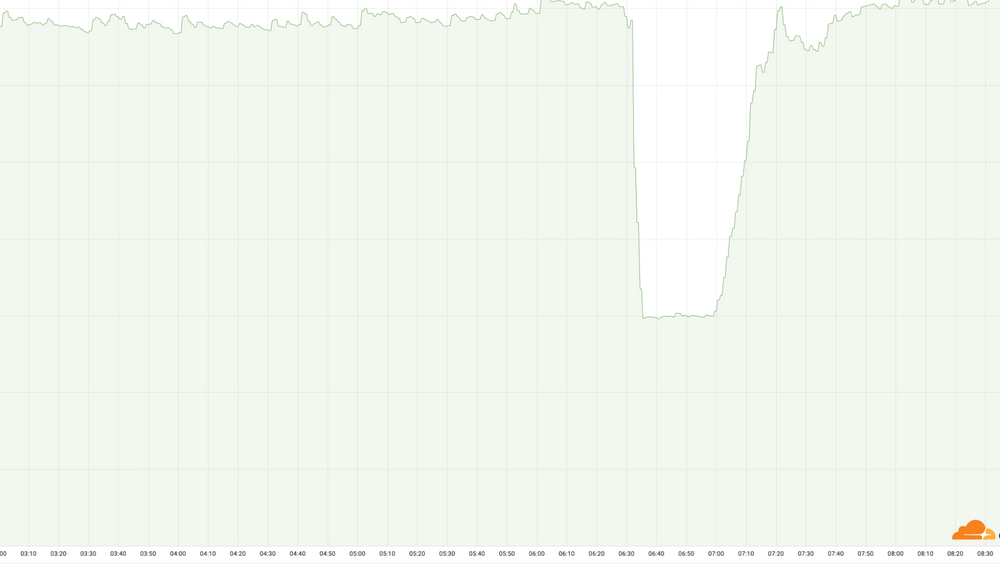
Tirsdag morgen norsk tid begynte Cloudflare å rulle ut en endring i nettverkskonfigurasjonen til selskapets datasentre. Den ble først rullet ut ved datasentrene med den gamle arkitekturen, noe som skjedde uten problemer. Men da den nye konfigurasjonen et par timer senere begynte å nå ut til de 19 datasentrene med MCP-arkitektur, gikk det galt. Samtlige ble utilgjengelige via internett.
Dette skal også ha gjort det vanskelig for Cloudflares teknikere å få tilgang til systemene for å rulle tilbake den gamle nettverkskonfigurasjonen. Men det er ikke første gang at nettopp dette skjer en stor aktør med distribuerte datasentre, så Cloudflare har noen rutiner og reserveløsninger for å få tilgang likevel.
Forlenget rettetid på grunn av kluss
Cloudflare oppgir at det brukte 26 minutter fra det ble erklært en hendelse og fram til rotårsaken var funnet. Deretter tok det 45 minutter før alle endringene var blitt reversert. Dette tok noe lengre tid enn nødvendig fordi noen av nettverksingeniørene klusset det litt til ved å reversere endringer som andre allerede hadde reversert. Det førte til at problemet gjenoppstod sporadisk.
Under nedetiden falt antallet besvarte forespørsler til Cloudflares systemer med omtrent 50 prosent. Flere detaljer om det som skjedde, er oppgitt i dette blogginnlegget.
Rammet av strømbrudd
Problemene som Microsoft og særlig selskapets kunder i Vest-Europa opplevde, varte mye lenger. De oppstod allerede klokken 01 natt til tirsdag og var ikke endelig løst før klokken 17.27 samme dag, skriver Microsoft i en foreløpig rapport.

Rotårsaken var et strømbrudd i infrastrukturen for trafikkstyringstjenester for brukere i primært Vest-Europa. Normalt skulle en annen infrastruktur ha tatt over tjenestene, men denne «fail over»-handlingen ble ikke fullført på riktig måte.
Dette førte til forsinkelser og aksessproblemer for flere Microsoft 365-tjenester, inkludert i alle fall Microsoft Teams, SharePoint Online, Microsoft Graph API, Exchange Online, Universal Print og OneDrive for Business.
I tillegg skal brukere ha opplevd problemer med å utføre søk og å bruke kalenderfunksjonalitet i tilknytning til de berørte tjenestene.



