
Apaches plattform Hadoop for applikasjoner som skal bearbeide petabyte-store mengder data, er i bruk hos aktører som Google, Facebook og Yahoo. Siden det dreier seg om friprog, har den i prinsippet vært fritt tilgjengelig for alle. I praksis er Hadoop så kompleks at de færreste prøver seg, selv om plattformen potensielt kan gi bedrifter langt større innsikt i egne data enn de fleste har i dag.
I oktober i fjor innså en gruppe eksperter innen åpen kildekode at brukervennlig Hadoop var en opplagt forretningsmulighet, og gikk sammen om å opprette selskapet Cloudera. Initiativtaker var Christophe Bisciglia, tidligere ansvarlig for Hadoop-implementasjonen i Google.
Cloudera har en enkel formålsparagraf: Tilby Hadoop-support til storbedrifter, med en distribusjon som er så enkel som mulig å installere, konfigurere og drifte.

I går kunngjorde Cloudera sin første Hadoop-distribusjon. Den er tilgjengelig gjennom en egen portal, my.cloudera.com, der man geleides av en veiviser til trinn for trinn å beskrive klyngen man har tenkt å kjøre Hadoop på. Denne spesifikasjonen lagres, slik at den er lett å endre når man trenger en ny Hadoop-utgave etter å ha forandret på klyngen.
Apache beskriver Hadoop som en plattform for å skrive og kjøre klyngede applikasjoner der enorme mengder data skal bearbeides. Den er laget i Java, og kan følgelig også beskrives som et Java-rammeverk for å støtte dataintensive distribuerte applikasjoner.
Hadoop er svært skalerbar, og kan lagre og bearbeide opptil mange petabytes med data. Applikasjonene kan kjøres på klynger bestående av mange tusen alminnelige datamaskiner. Dataene distribueres og bearbeides parallelt. Systemet har en egen form for feiltoleranse som gjør at det automatisk gjentar mislykkede regneoppgaver helt til de utføres korrekt.
I sin nåværende form er Hadoop demonstrert på klynger med 2000 noder. Målet for dagens design er å kunne kjøre på 10 000 noder.
Hadoop implementerer en programmeringsmodell utviklet av Google for å forenkle dataprosessering i store klynger: MapReduce. Denne modellen gjør det mulig å dele en applikasjon i mindre arbeidsoppgaver. I Hadoop virker MapReduce i spann med løsningens eget distribuerte filsystem, HDFS (Hadoop distributed file system). HDFS tar datablokker, replikerer dem, og fordeler kopier rundt omkring i nodene i klyngen, slik at applikasjonens MapReduce-oppgaver kan prosessere dataene på stedet. Denne prosessen illustreres slik:
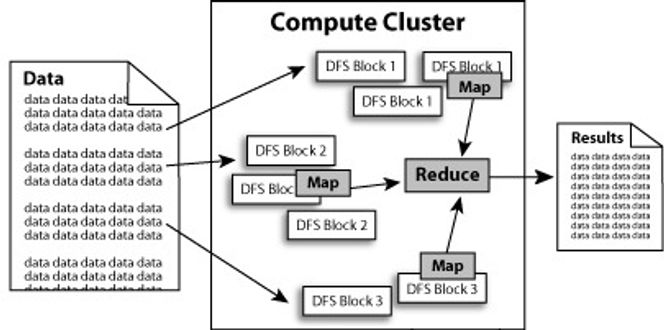
Feiltoleransen i Hadoop skyldes egenskaper i filsystemet HDFS.
MapReduce og HDFS hører begge til i Hadoop-kjernen. Utenom kjernen – Hadoop Core – omfatter prosjektet ytterligere fire komponenter:
- HBase: en database bygget på Hadoop Core
- Pig: et programmeringsspråk og kjørerammeverk for parallell databehandling
- ZooKeeper: et system for å koordinere distribuerte applikasjoner i et høytilgjengelighetsmiljø
- Hive: en infrastruktur for datavarehus, med funksjoner for sammenfatning, spørring og analyse av data
Cloudera vil inntil videre distribuere sin Hadoop fritt, under lisensen Apache 2. I sin alminnelige form kan den kjøres på Linux, Windows eller MacOS. I sin enkleste utgave kommer den med det minimale som trengs for utprøving, det vil si en master server og én node.
Alternative distribusjonsformer er en RPM-pakke for Red Hat, en image for Amazon EC2, og en prekonfigurert VMware-image.
Les også:
- [18.02.2010] Friprog kloner Googles infrastruktur
- [03.11.2009] Yahoo gir bort webtrafikk-monster
- [30.07.2008] HP, Intel og Yahoo sammen for «nettskyen»
- [02.05.2008] Banebrytende allianse mellom IBM og Google

