Kunstig intelligens
Mozilla: – Monopol på stemmedata minner om patent på mus og tastatur
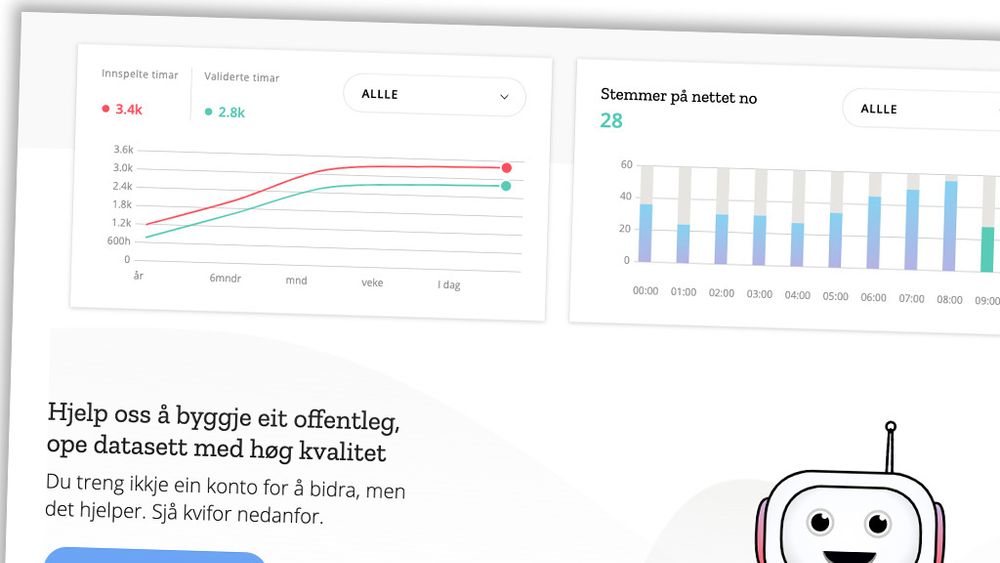
Mozilla har samlet inn stemmedata fra nesten 200.000 i et forsøk på å bryte gigantenes datamonopol.
Kommentarer
Du må være innlogget hos Ifrågasätt for å kommentere. Bruk BankID for automatisk oppretting av brukerkonto. Du kan kommentere under fullt navn eller med kallenavn.

