NRK betaler for forskningen som kom i stand i 1995 etter initiativ fra daværende direktør i NRK Tekst-TV Rolleiv Solholm. Prosjektet har trukket i langdrag fordi forskerne har vært opptatt med andre gjøremål. Nå er planen at ONCAP - "On-line Captioning of Live TV-programs Using Speech Recognition" - skal være klar til en endelig demonstrasjon innen utgangen av 2000.
- Så vidt vi vet, finnes ikke tilsvarende prosjekter i andre land, sier forsker Erik Harborg ved SINTEF som utvikler ONCAP sammen med kollega Trym Holter, og Magne Hallstein Johnsen og Torbjørn Svendsen fra NTNU.
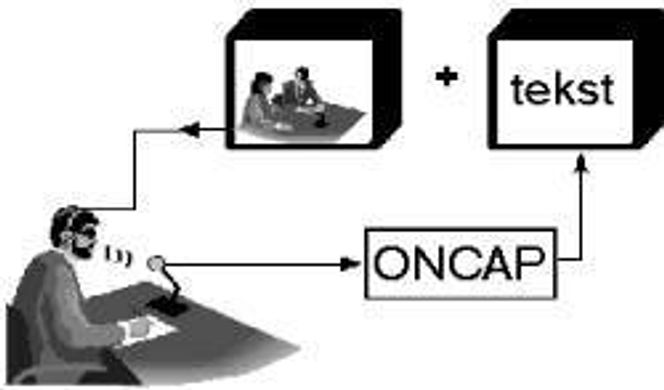
Prosjektet tar ikke sikte på å gjenkjenne løpende filmdialoger eller tale i direktesendte innslag. Ideen er i stedet å la en egen og trenet kommentator følge med på skjermen, og beskrive det som skjer. Det er kommentatorens taleflom som kjøres gjennom en talegjenkjenner, og framstilles løpende som tekst. I England og Tyskland brukes en annen metode, der en trenet operatør taster talen direkte inn i tekstsystemet gjennom en spesialkonstruert maskin.
- Etter NRKs syn har den metoden så mange ulemper at de ikke vil bruke den i Norge, forteller Harborg. - Erfaringsmessig tar det to års opplæring før en operatør kan skrive raskt nok. Da er de gjerne så lei at de krever å få arbeide med andre ting. De som holder ut, produserer gjerne så mye tekst at brukerne ikke greier å henge med.
Oppgaven til ONCAP-operatøren er ikke å gjengi den opprinnelige talen, men å komprimere den i passende porsjoner. Operatøren følger med på skjermen og beskriver fortløpende det han hører. Om nødvendig kan produsenten legge inn en kort forsinkelse for å bedre synkroniseringen mellom bilde og tekst.
- Erfaringen viser at en del personer takler dette rimelig greit uten at de trenger noen særlig opplæringstid. Andre folk fikser det ikke. Arbeidet likner litt på det en simultan tolk må gjøre.
Harborg understreker at det er forskjell mellom ONCAP og et rent dikteringssystem.
- Rene dikteringssystemer forutsetter pen og ren tale i fullstendige setninger. Bruken av ONCAP må ta høyde for nølelyder, hark og host, og halvkveda setninger. Det er ingen enkel oppgave for kommentatorene å få til flytende og grammatisk korrekte setninger hele tiden.
Dette kravet får blant annet følger for den språkmodellen som blir brukt. Talegjenkjenning avbilder lyder mot ord. For å bedre gjenkjenningen har ONCAP-forskerne valgt en språkmodell som tar hensyn til hvor hyppig ordpar opptrer i tale. Hyppighetene er samlet på grunnlag av taleopptak fra NRK. Å legge ordparhyppighet til grunn for en språkmodell er noe Harborg mener har allmenn interesse, utover det norske språkfellesskapet. Her kan ONCAP-prosjektet bidra med viktige erfaringer for andre språk.
På norsk kompliseres denne språkmodellen av at mange ord er sammensatte. Også her høstes erfaringer som kan komme til nytte på andre språk, blant annet tysk.
Ordforrådet spiller en stor rolle. Harborg mener at 20.000 ord er tilstrekkelig for talematerialdatabasen. Da holder det med mellom tjue og tretti timer tale. I praktisk bruk vil ordforrådet deles i to, en allmenn del og en som er tilpasset emnet for det aktuelle tv-programmet. Skal kommentatoren arbeide med norsk politikk, lastes et eget ordforråd med både spesialuttrykk og særlig navn på aktuelle politikere.
Harborg har presentert prosjektet ved flere internasjonale forskersamlinger, men ikke demonstrert det.
- Foreløpig er det for mange feil, og det går for sakte. Ofte er feilene helt ubetydelige, men i ekstreme tilfeller blir betydningen snudd helt om. Vi skal bli fornøyd når vi kommer over 95 prosent i andel korrekt gjengitte ord.
Resultater som Harborg og hans medarbeidere har publisert, viser en vesentlig kvalitetshevning når systemet legges til rette for den individuelle kommentatoren. Det øker andelen korrekt gjenkjente ord fra mellom 70 og 80 prosent til rundt 90 prosent. Korrekt gjengivelse av setninger varierer sterkt avhengig av taleren, mellom 23 og 46 prosent. Gis systemet anledning til å ta hensyn til en spesiell taler, øker andel til mellom 38 og 58 prosent.
Når problemene med språkmodellen er løst, regner ikke Harborg med at det vil by på store problemer å få ned hastigheten, siden det nåværende arbeidet kjøres gjennom utviklingsverktøyet, og ikke i et praktisk bruksmiljø. Et ferdig system vil legge store beslag på minne og prosessorkraft. erfaringer med annen taleteknologi tyder på at en vanlig 200 MHz Pentium vil gi tilstrekkelig ytelse. NRK tenker seg systemet kjørt på en PC med Windows NT og et grensesnitt som ikke stiller spesielle krav til kommentatorenes tekniske kvalifikasjoner.
Harborg forsikrer at det er god kontakt mellom ONCAP-forskerne og miljøet rundt Nordisk Språkteknologi på Voss, og at ordninger er opprettet for å hindre at kreftene ikke sløses på å gjenoppfinne hjul etter hverandre.