Kunstig intelligens-teknologi går fremover med stormskritt, og blant områdene teknologien testes ut på er dataspill, som brukes som et mål på hvor langt forskningen har kommet. Blant andre The Verge melder nå at den Google-eide, kunstig intelligens-løsningen DeepMind nå har gjort imponerende fremskritt på feltet.
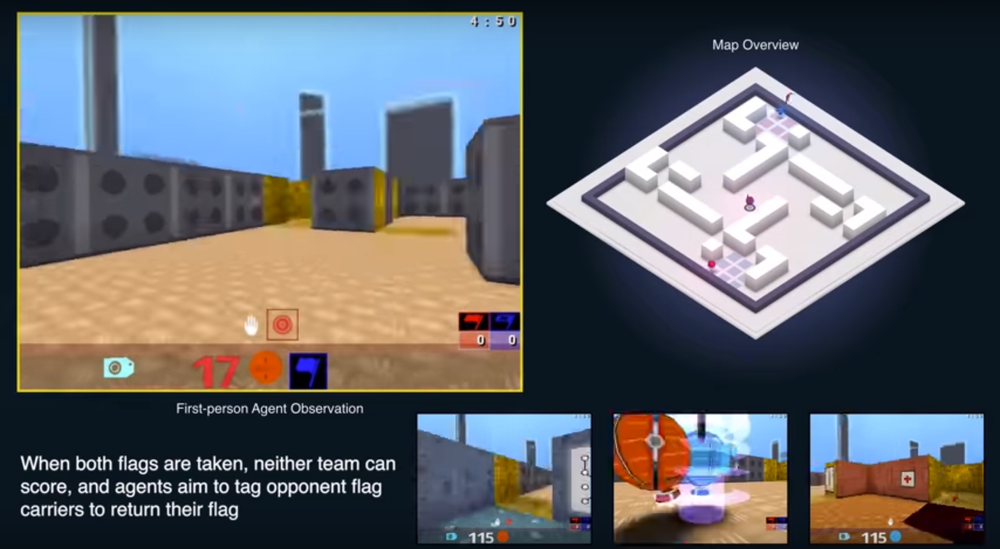
På DeepMind-bloggen kan man lese at forskere har lykkes med å trene opp DeepMind-systemet i en slik grad at det overgår menneskelig prestasjon i lagbaserte skytespill – nærmere bestemt spillet Quake III Arena.
Systemet er trent opp i en Quake III-modus som heter «Capture the Flag», som går ut på å stjele et flagg fra motstanderlaget mens man samtidig forsvarer sitt eget flagg. Modusen byr på kompliserte dynamikker siden man både må samarbeide med andre aktører, konkurrere mot det andre laget, tilpasse seg situasjoner på sparket og legge helhetlige strategier.
Forsterket læring
Treningen er gjort ved hjelp av en opplæringsmetode innen maskinlæring som kalles «reinforcement learning», eller «forsterkende læring» på norsk. Det innebærer i korte trekk å finne løsningen til et problem ved å definere den ideelle løsningen innenfor en bestemt kontekst, og gi belønninger eller straff for hvorvidt oppførselen fører agenten nærmere eller lengre fra løsningen.
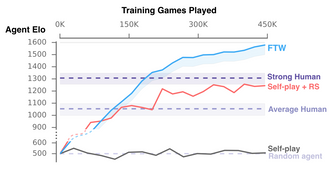
DeepMind-forskernes fremgangsmåte var å trene opp hele grupper av ulike agenter samtidig ved å la dem lære fra hverandre, og forskernes metode innebar også å la agentene lære sine egne, interne belønningssignaler slik at hver agent kan generere sine egne mål.
De kunstig intelligente agentene ble testet på tilfeldig genererte kart, slik at de måtte lære seg hvert nye kart underveis, og de ble heller ikke instruert i noen av reglene, men måtte lære alt dette på egen hånd. DeepMind-forskerne kjørte en turnering med 40 spillere, hvor agenter og mennesker ble vilkårlig matchet. Ifølge forskerne overgikk agentene prestasjonen til de menneskelige spillerne, også når det gjaldt evne til samarbeid.
Selv om teknologien i dette tilfellet ble testet med spill sier forskerne at arbeidet representerer et viktig, generelt bidrag til forskningen innen kunstig intelligens, særlig innen «forsterket læring»-grenen av feltet. Flere detaljer kan du finne på DeepMind-bloggen, og se også video under.
Les også: Kina svarer når Google lanserer AI-brikke »


