
Nvidia slo virkelig på lanserings-stortromma torsdag kveld – hvor høydepunktet var selskapets nye GPU-arkitektur, Ampere. Dette er etterfølgeren til Volta-arkitekturen som brukes i blant annet Titan V-grafikkortene og i Tesla V100 – en GPU beregnet på datasentre.
Den første GPU-en som tar i bruk Ampere-arkitekturen blir Nvidia A100. Ampere og A100 er ikke noe som vil finne veien inn i gaming-PC-en på gutterommet med det første, men er beregnet på bruk i datasentre og i superdatamaskiner. Den nye grafikkprosessoren skal blant annet ha vesentlig bedre ytelse ved bruk innenfor maskinlæring og kunstig intelligens enn forrige generasjon.
54 milliarder transistorer og verdens største 7 nm-brikke
A100-brikken er produsert med en 7 nanometer produksjonsprosess og består av vanvittige 54 milliarder transistorer. Det resulterer i en brikke med et areal på hele 826 mm², som ifølge Nvidia skal gjøre den til verdens største 7 nanometer-brikke.
Brikken inneholder 6192 CUDA-kjerner i tillegg til tredje generasjon Tensor-kjerner basert på den nye Ampere-arkitekturen. Tensor-kjernene akselererer maskinlæring og kunstig intelligens, og ifølge Nvidia skal de 432 Tensor-kjernene i A100 levere en ytelse på opptil 19,5 TFLOPS (1 TFLOP er 1000 milliarder flyttallsoperasjoner i sekundet). Det er mer enn dobbelt så raskt som Nvidias tidligere Volta V100-GPU.
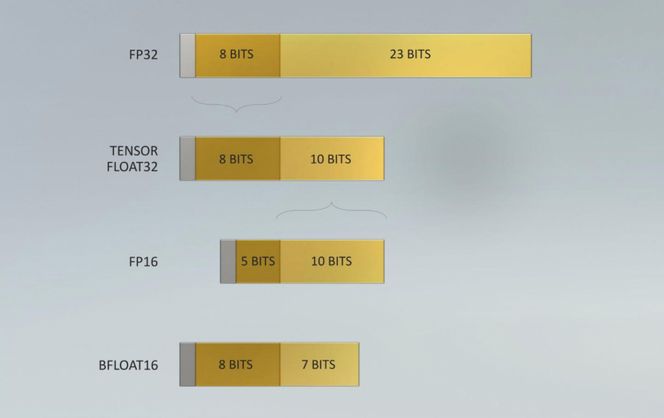
En stor nyhet er at A100 støtter et nytt «matematikkformat» kalt TensorFloat-32 (TF32). Det nye formatet kan representere det samme tallområdet som flyttallsformatet FP32, men med redusert presisjon (tilsvarende FP16). TF32-formatet kan kombinert med andre nye teknologier i A100-brikken gi så mye som 20 ganger bedre ytelse på trening av maskinlæringsalgoritmer.
GPU-en har en minnebåndbredde på 1,6 TB/sek, en økning fra 900 GB/sek sammenlignet med V100. Det er støtte for 40 GB HBM2-minne. A100-GPU-ene kommuniserer med CPU-en via Nvidias nye NVLink 3-buss som har en båndbredde på 600 GB/sek. Dette er en dobling sammenlignet med NVLink 2 som brukes i V100.
5 petaflops i en boks
Det har gått to år siden Nvidia lanserte DGX-2, en maskin spesiallaget for å bruke innenfor blant annet kunstig intelligens, og som kombinerer en rekke av selskapets GPU-er i én server. Her i Norge har Universitetet i Agder bygget en superdatamaskin i verdensklasse basert på totalt åtte DGX-2-bokser.

Nå har Nvidia lansert etterfølgeren DGX A100, hvor de slår sammen åtte av de nye A100-GPU-ene. DGX A100 har totalt 320 GB grafikkminne og en samlet minnebåndbredde på 12,4 TB/sek. Den nye boksen har en ytelse på 5 petaflops, mens DGX-2 lå på 2 petaflops.

DGX A100 har ellers to AMD Rome CPU-er og 1 TB RAM, 15 TB 4. generasjon NVMe SSD (som er dobbelt så raskt som 3. generasjon), samt 9 Mellanox ConnectX-6 VPI nettverkskort med 200 GB/sek båndbredde hver.
Det er mulig å enten bruke én DGX A100 som et frittstående system, eller koble sammen mange av dem. Ifølge Nvidia vil et rackskap med fem DGX A100 kunne erstatte et helt datasenter for AI-trening og «inference»-infrastruktur med et strømforbruk på en tjuendedel, til en tiendedel av kostnaden.
Prislappen på herligheten starter på 199.000 dollar.
Hvis du vil lese mer om Ampera-arkitekturen, har Nvidia gått enda mer i dybden i dette blogginnlegget.

Skal få fart på 10 nm: Nå kommer Intels Tiger Lake-prosessorer